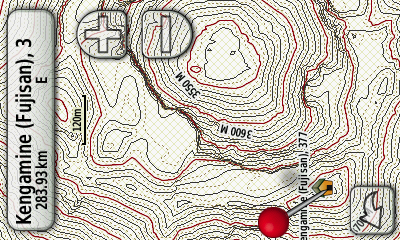
今回は5m補助線付き地形図の自作に挑戦しました。以前作成した10m間隔の等高線と比較してより細かく地形が把握出来るようになる、と期待します。
環境
いつものLinux環境ですが、今回はメモリが足らないので増設しました。現環境での最大搭載量です。
- OS:Ubuntu 18.04(64bit)
- CPU:Core i5-4670 @3.4GHz
- Memory:32GByte(DDR3)
- HDD:2TByte
地形図に5m補助線を追加するためにやったこと
メモリ増設
今まで作成した地形図の等高線は10m間隔でした。ここに5mの補助線を追加するにあたりどうしてもやらなければいけないことがありました。
それは、メモリ増設です。
今までメモリは16GByte積んでいましたが10m間隔でもカツカツでした。5m間隔とすると単純に考えても倍以上になるので、ヤフオクで中古メモリ8GByte x2枚を購入して増設することにしました。これでメモリ搭載量はMaxの32GByteとなりました。

ヤフオクでDDR3メモリ8GByte2枚を落札しました。

これで最大搭載量の32GByteとなりました。当時はこんなに積むなんて考えもしませんでしたね。
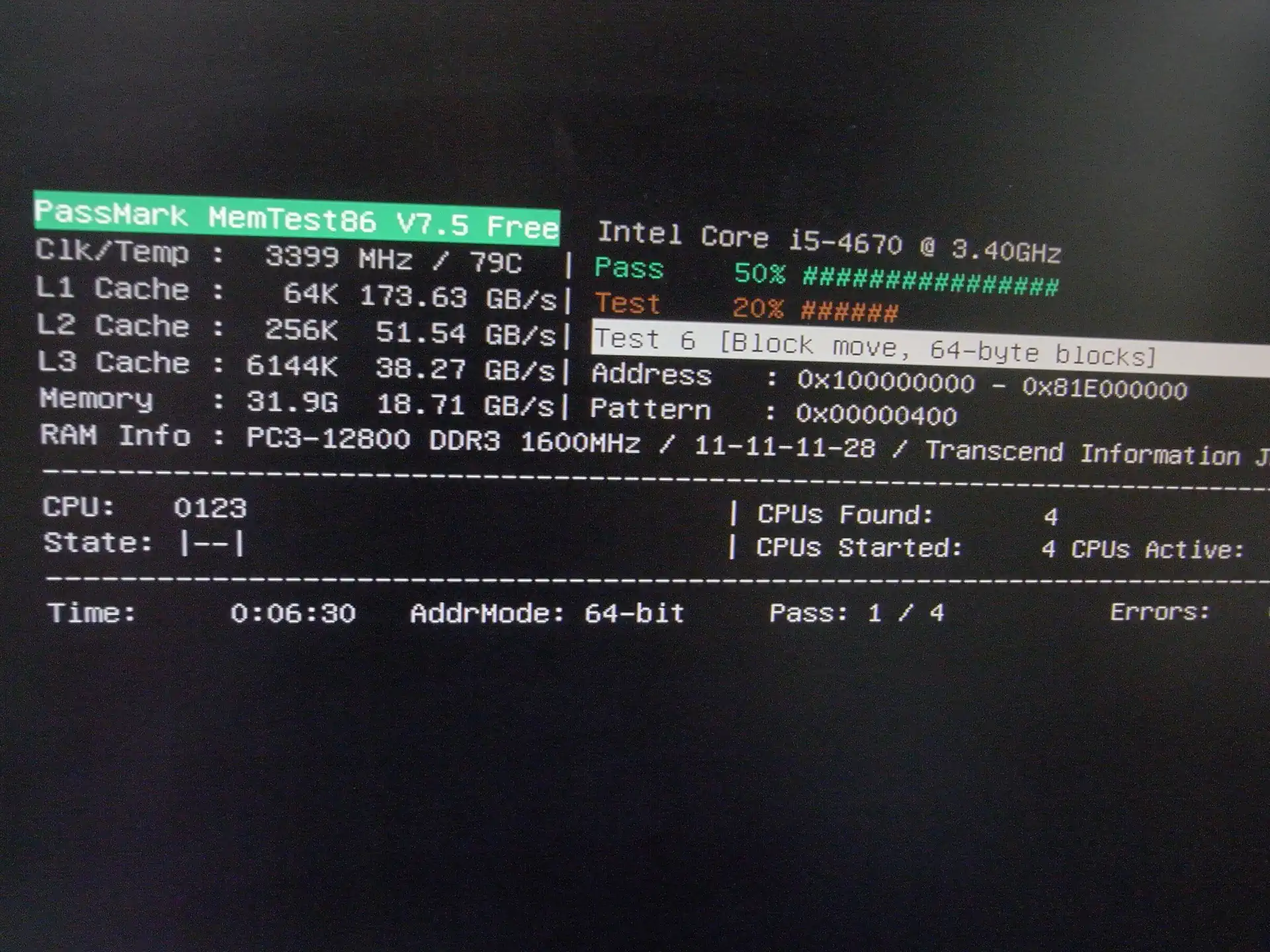
念のためmemtestでチェック。結果はOKです。
zswapを有効にする
実際のところ本州の等高線を丸ごと生成するには32GByteあっても不足しています。というかやってみたら全然足りませんでした。。。そこでzswapを有効にしてメモリ圧縮を行うことでなんとか凌ごうと考えました。
root@ubuntu18:~# echo lz4 > /sys/module/zswap/parameters/compressor root@ubuntu18:~# echo 20 > /sys/module/zswap/parameters/max_pool_percent root@ubuntu18:~# echo y > /sys/module/zswap/parameters/enabled
結果として途中までは上手く行ったのですが、日本で最も等高線が入り組んでいると思われる南アルプス辺りに差し掛かってしばらくした辺りでメモリ不足で落ちました。スワップ領域をもっと大量に取っていればもしかするといけたかもしれないのですが・・・。
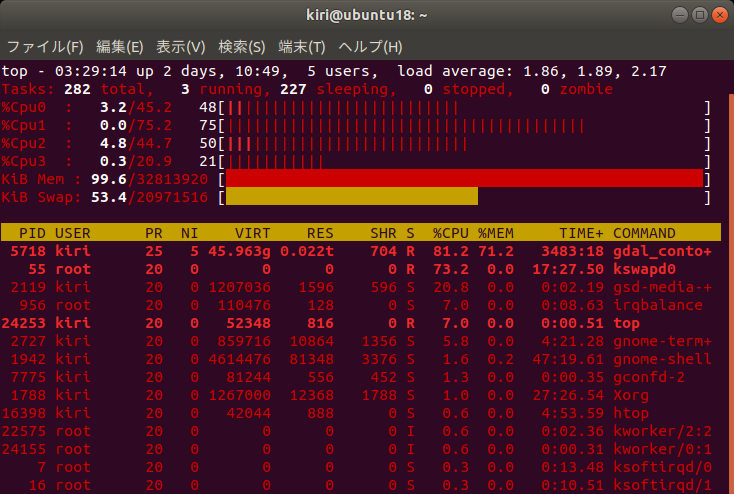
コレを見て、やばいかもと思っていたら案の定メモリ不足で落ちてしまいました。ここまで3日かかったのですが・・・がっくり。
本州エリアを3分割する
ことここにいたり本州丸ごと処理するという横着は断念せざるを得ませんでした。リトライするには時間がかかりすぎます。そこで本州を3分割することにしました。途中で等高線が途切れてしまいますがやむを得ません。
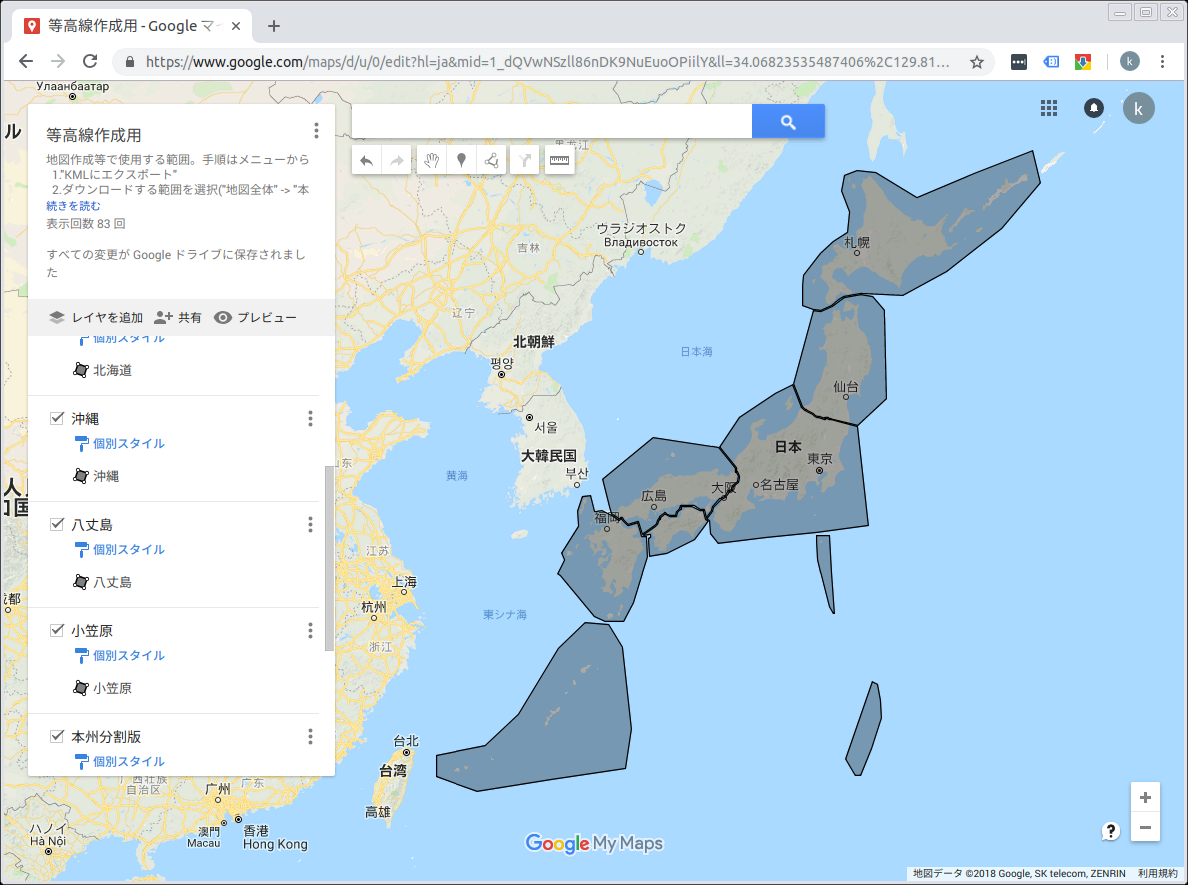
無念の本州3分割となりました。いつかリベンジしたいと思います。
等高線の作成
手順そのものは10m間隔の時と変わりありません。下記の記事と同様にgdalを使って等高線を作ります。
また、元となるDEMにはDEM5A/5Bの不足分をDEM10Bで補完したものを使用しました。
日本から指定範囲の切り出しを行う
まず日本をいくつかのエリアに区切って切り出しを行います。前回は地続きとなる範囲で切り出しましたが、私の環境だと本州を一発で終わらせるにはメモリが足らず、今回は本州を分割にしています。
$ gdal_translate -of vrt -projwin 130.625 42.916666667 142.125 33.416666667 -a_nodata -9999 ./japan-dem5_10.vrt /vsistdout/ | gdalwarp --config GDAL_CACHEMAX 500 -wm 500 -multi -cutline ./../kml/Honshu_part1.kml -wo "OPTIMIZE_SIZE=YES" -co "BIGTIFF=YES" -co "COMPRESS=LZW" -co "PREDICTOR=2" -co "NUM_THREADS=ALL_CPUS" /vsistdin/ ./japan-honshu_part1.tif $ gdal_translate -of vrt -projwin 130.625 42.916666667 142.125 33.416666667 -a_nodata -9999 ./japan-dem5_10.vrt /vsistdout/ | gdalwarp --config GDAL_CACHEMAX 500 -wm 500 -multi -cutline ./../kml/Honshu_part2.kml -wo "OPTIMIZE_SIZE=YES" -co "BIGTIFF=YES" -co "COMPRESS=LZW" -co "PREDICTOR=2" -co "NUM_THREADS=ALL_CPUS" /vsistdin/ ./japan-honshu_part1.tif $ gdal_translate -of vrt -projwin 130.625 42.916666667 142.125 33.416666667 -a_nodata -9999 ./japan-dem5_10.vrt /vsistdout/ | gdalwarp --config GDAL_CACHEMAX 500 -wm 500 -multi -cutline ./../kml/Honshu_part3.kml -wo "OPTIMIZE_SIZE=YES" -co "BIGTIFF=YES" -co "COMPRESS=LZW" -co "PREDICTOR=2" -co "NUM_THREADS=ALL_CPUS" /vsistdin/ ./japan-honshu_part1.tif ...
本州以外も同様に処理します。
等高線を5m間隔で生成する
gdal_contourで切り出したGeoTIFFから等高線を生成します。ここでは”-i”オプションで等高線の間隔を5mに指定しました。所要時間は3日+αと行った感じでしょうか。最もメモリを必要とするフェーズです。
$ mkdir contour
$ find . -name “*.tif” -exec gdal_contour -a ele -i 5.0 -f CSV -dsco “GEOMETRY=AS_WKT” {} ./contour/{}.csv ;
OSM形式に変換する
次にOSM(xml)形式ファイルへの変換を行います。以前の記事と比較すると、今回はNode数が大幅に増加するのでID番号を振り直しています。また、不要な属性を出力してファイルサイズが大きくなっていたのでスクリプトを修正してあります。
# convert to osm $ cd ./contour $ mkdir osm $ cd ./osm # 北海道 $ echo -e "10000000000n40000000000n50000000000" > id_hokkaido.txt $ python /data/git/suke-blog/ogr2osm/ogr2osm.py --no-memory-copy --separate-id --idfile=./id_hokkaido.txt --saveid=./id_hokkaido.txt --positive-id --sequential-output --translation=contour.py ../japan-hokkaido-5m.csv # 本州 $ echo -e "13000000000n41000000000n51000000000" > id_honshu.txt $ python /data/git/suke-blog/ogr2osm/ogr2osm.py --no-memory-copy --separate-id --idfile=./id_honshu.txt --saveid=./id_honshu.txt --positive-id --sequential-output --translation=contour.py ../japan-honshu-part1.csv $ python /data/git/suke-blog/ogr2osm/ogr2osm.py --no-memory-copy --separate-id --idfile=./id_honshu.txt --saveid=./id_honshu.txt --positive-id --sequential-output --translation=contour.py ../japan-honshu-part2.csv $ python /data/git/suke-blog/ogr2osm/ogr2osm.py --no-memory-copy --separate-id --idfile=./id_honshu.txt --saveid=./id_honshu.txt --positive-id --sequential-output --translation=contour.py ../japan-honshu-part3.csv # 四国 $ echo -e "20000000000n42000000000n54000000000" > id_sikoku.txt $ python /data/git/suke-blog/ogr2osm/ogr2osm.py --no-memory-copy --separate-id --idfile=./id_sikoku.txt --saveid=./id_sikoku.txt --positive-id --sequential-output --translation=contour.py ../japan-sikoku-5m.csv # 九州 $ echo -e "21000000000n43000000000n55000000000" > id_kyushu.txt $ python /data/git/suke-blog/ogr2osm/ogr2osm.py --no-memory-copy --separate-id --idfile=./id_kyushu.txt --saveid=./id_kyushu.txt --positive-id --sequential-output --translation=contour.py ../japan-kyushu-5m.csv # 沖縄 $ echo -e "22000000000n44000000000n56000000000" > id_okinawa.txt $ python /data/git/suke-blog/ogr2osm/ogr2osm.py --no-memory-copy --separate-id --idfile=./id_okinawa.txt --saveid=./id_okinawa.txt --positive-id --sequential-output --translation=contour.py ../japan-okinawa-5m.csv # 八丈島周辺 $ echo -e "23000000000n45000000000n57000000000" > id_hachijojima.txt $ python /data/git/suke-blog/ogr2osm/ogr2osm.py --no-memory-copy --separate-id --idfile=./id_hachijojima.txt --saveid=./id_hachijojima.txt --positive-id --sequential-output --translation=contour.py ../japan-hachijojima.csv # 小笠原諸島周辺 $ echo -e "24000000000n46000000000n58000000000" > id_ogasawara.txt $ python /data/git/suke-blog/ogr2osm/ogr2osm.py --no-memory-copy --separate-id --idfile=./id_ogasawara.txt --saveid=./id_ogasawara.txt --positive-id --sequential-output --translation=contour.py ../japan-ogasawara.csv # その他 $ echo -e "25000000000n47000000000n59000000000" > id_others.txt $ python /data/git/suke-blog/ogr2osm/ogr2osm.py --no-memory-copy --separate-id --idfile=./id_others.txt --saveid=./id_others.txt --positive-id --sequential-output --translation=contour.py ../FG-GML-3036-50-DEM10B.csv $ python /data/git/suke-blog/ogr2osm/ogr2osm.py --no-memory-copy --separate-id --idfile=./id_others.txt --saveid=./id_others.txt --positive-id --sequential-output --translation=contour.py ../FG-GML-3653-37-DEM10B.csv
osm(xml)が出来上がったら、osmconvertを使ってo5m形式に変換します。
$ find . -name “*.osm” -exec osmconvert {} --out-o5m -o={}.o5m ;
以前は日本全体で1ファイルにまとめましたが、今回は大きすぎてGarmin形式に変換したときにファイルサイズが上限である4GByteを超えてしまいます。なので北海道/本州/四国・九州・沖縄といった感じに分けて纏めます。
$ osmconvert japan-hokkaido-5m.osm.o5m --out-pbf -o=japan-hokkaido-5m.osm.pbf $ osmconvert japan-honshu-*.osm.o5m --out-pbf -o=japan-dem5-honshu-5m.osm.pbf $ osmconvert --out-pbf japan-sikoku-5m.osm.o5m japan-kyushu-5m.osm.o5m japan-okinawa-5m.osm.o5m japan-ogasawara-5m.osm.o5m japan-hachijojima-5m.osm.o5m -o=japan-kyushu-sikoku-okinawa-ogasawara-5m.osm.pbf
ファイルサイズはpbf形式で17GByteとなりました。流石に巨大です。
$ du -bhc *.pbf 2.8G japan-contour-dem5-hokkaido-5m.osm.pbf 11G japan-contour-dem5-honshu-5m.osm.pbf 3.1G japan-contour-dem5-kyushu-sikoku-okinawa-5m.osm.pbf 17G 合計
Garmin形式に変換する
出来上がった等高線をGarmin GPSで読み込める形式に変換します。このあたりの手順は以下の記事を参照ください。
等高線を確認する
出来上がった地図をGPSに転送して確認しました。ノードの数が倍以上に膨れただけあって動きが少し重く感じますが、表示そのものは問題ないようです。
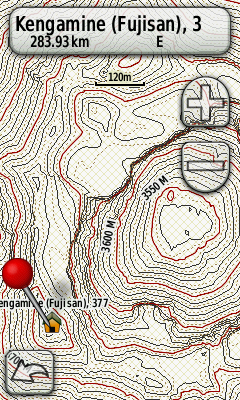
テストで生成した富士山の地形図
ただ、この5m補助線ありの地形図はとてもファイルサイズが大きくて、特に本州は分割しない限りOpenStreetMapの地図要素を含めて1ファイルに纏めるのは無理そうです。別の地図と組み合わせて運用するのが妥当なのかな。
所感
ともかくメモリが必要といった感じです。。今のPCを組んだ当初は16GByteもメモリ積んどけば余裕とか考えていましたが、全然足りません。メモリ増設にくわえて悪あがきにzswapを有効にして、それでも足らず本州三分割となりました。分割すると等高線がちょん切れるので避けたかったのですが・・・いつかリベンジしたいと思います。
コメント